Can an LLM Learn to Investigate Another LLM?
I built Circuit Detective in under 48 hours for the Meta x Hugging Face x PyTorch hackathon finals. The project asks whether a small language-model (<2B params) agent can learn to investigate transformer circuits with the same tools a mechanistic-interpretability researcher would use: inspection, ablation, activation probing, and behavior-delta measurement.
TLDR: Phase 1 taught the agent to inspect and submit. The causal version exposed the harder problem: the agent could get the right answer without causal evidence, or gather evidence and fail to submit. Fixing that required changing the environment, not just training longer.
The gap: training the process
Chess has thousands of RL training environments. Go has AlphaZero. Atari has benchmarks built specifically to test planning and control. Mechanistic interpretability has excellent tooling, but it has not had a dedicated environment for training an agent to do the work.
TransformerLens, ACDC, and SAELens make circuit analysis much easier than it used to be. The field also has concrete circuit discoveries: induction heads, IOI name-mover heads, and successor heads. The workflow is structured: form a hypothesis, run an ablation, measure the behavior drop, update beliefs. What was missing was a way to train that workflow as an agent policy.
Most circuit discoveries still come from human researchers spending weeks forming hypotheses, running activation patches, comparing logit-diff scores, and iterating. ACDC automates part of the search, but it is a greedy graph-search algorithm. It does not learn from experience, and it does not become better by seeing more tasks.
Circuit Detective is my attempt to turn this into a trainable environment. The narrow question was: can a small language model learn the basic mechanistic-interpretability protocol of inspect, ablate, validate, and submit?
Watch the agent work
Before reward functions or training curves, here is what a successful Phase 2 episode looks like in the planted-lite arena after training:

The agent receives a frozen transformer and a budget of four tool calls. It inspects the candidate heads, sees that the top-ranked head is a decoy, ablates both candidates, watches the behavior drop, and submits the head whose ablation changed the model’s behavior.
The before-training trace stops after the two ablate_head calls. It has the evidence and never submits. That one missing tool call is the Phase 2 problem.
The environment
Circuit Detective is an OpenEnv-compliant environment where a language-model agent investigates a frozen transformer with mechanistic-interpretability tools and submits a candidate circuit. OpenEnv gives RL environments a standard action, observation, and reward interface. Circuit Detective is publicly hosted at ehsaaniqbal/circuit-detective, validates with openenv validate, and follows the usual Gym-style reset / step / state pattern.
The agent model is Qwen/Qwen3.5-2B. The trainer is HF TRL GRPOTrainer with PEFT/QLoRA on HF Jobs a10g-large.
The tool surface is close to what a human interpretability researcher actually uses:
| Tool | What it does | Human analogue |
|---|---|---|
inspect_induction_scores(top_k) | Rank attention heads by behavioral metric | ”Which heads look interesting?” |
ablate_head(layer, head) | Zero-ablate one head, measure behavior drop | ”What happens if I remove this?” |
run_probe | Measure baseline behavior on a fixed probe batch | ”Establish the baseline first” |
submit_circuit(heads) | Submit candidate set and end the episode | ”I’m confident in this circuit” |
Ground truth is deterministic. It comes from published circuit research and from the planted-lite environment’s known causal head. No LLM-as-judge is in the training reward path. The reward uses a composable rubric with five components:
| Rubric component | What it measures |
|---|---|
tool_format | Did the agent produce valid tool calls? |
evidence_gathering | Did it call inspect_induction_scores? |
intervention | Did it call ablate_head? |
causal_validation | Did the submitted head have a verified behavior delta? |
final_answer_f1 | Precision/recall of the submitted head set |
These five numbers are more useful than a single success metric. That became obvious in Phase 2.
Phase 1: can the agent learn the protocol?
Phase 1 is deliberately narrow: localize the dominant induction head, L1H6, in TransformerLens’ attn-only-2l toy model and submit it. The correct answer is fixed. The challenge is not knowing the answer; it is learning to execute the right tool-call sequence under GRPO.
Pure GRPO without supervised warm-start failed immediately. The model rarely sampled submit_circuit, so GRPO had almost no useful signal to grade. Adding a tiny SFT warm-start changed the run. The SFT data was synthetic expert traces showing the minimum inspect -> submit protocol.
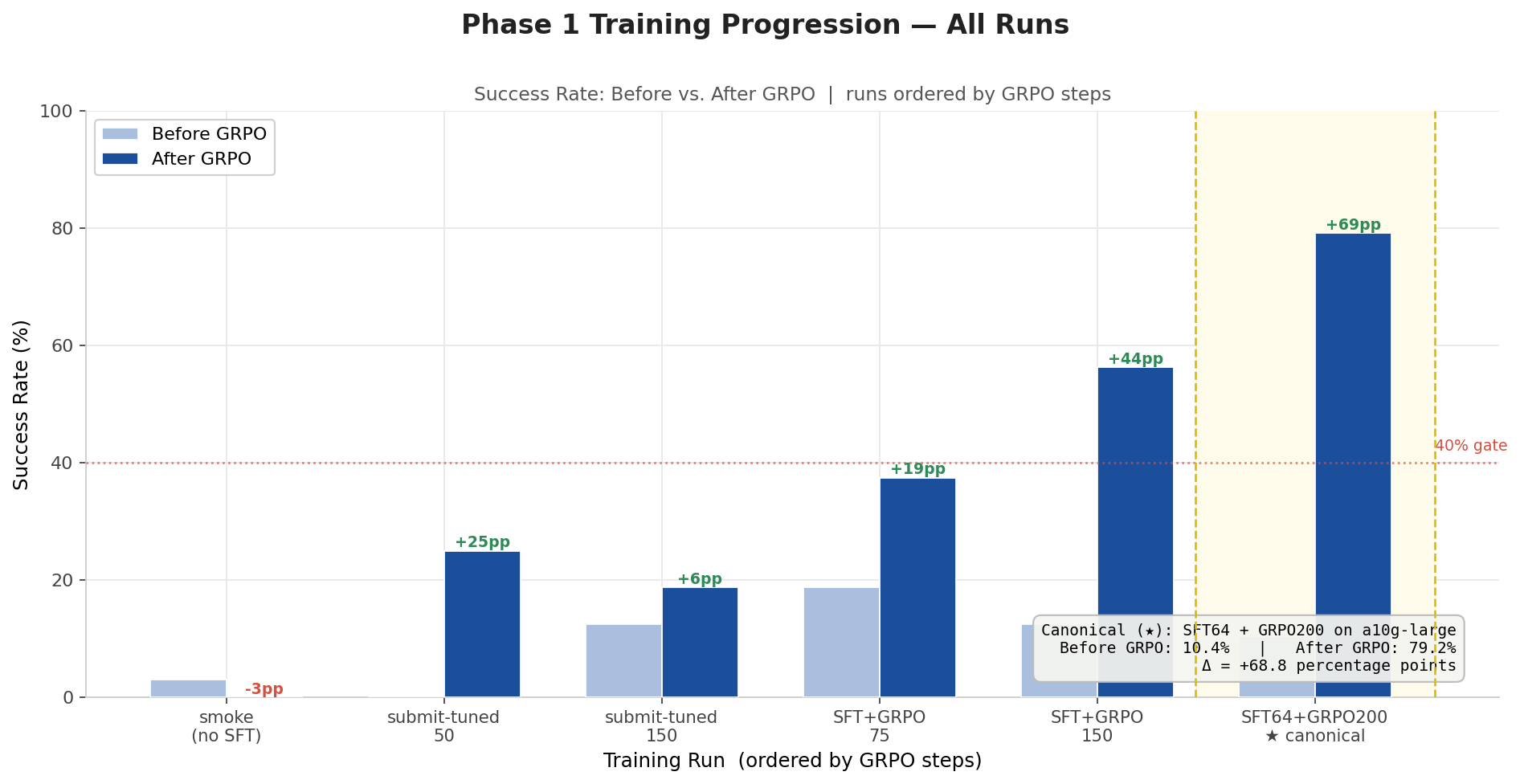
Before-vs-after success rate across six Phase 1 runs. Pure shaped GRPO plateaued under 25%. The SFT warm-start unlocked the gradient signal. The canonical SFT64 + GRPO200 run cleared the 40% gate by 69 percentage points.
The canonical run passed the hackathon gate:
| Metric | Before training | After training |
|---|---|---|
| Success rate | 10.4% | 79.2% |
| Submit rate | 10.4% | 81.2% |
| Mean F1 | 0.104 | 0.792 |
| Mean reward | 0.086 | 1.207 |
| Eval rollouts | 48 | 48 |
Trained adapter: circuit-detective-qwen35-2b-phase1-sft64-grpo200-lora.
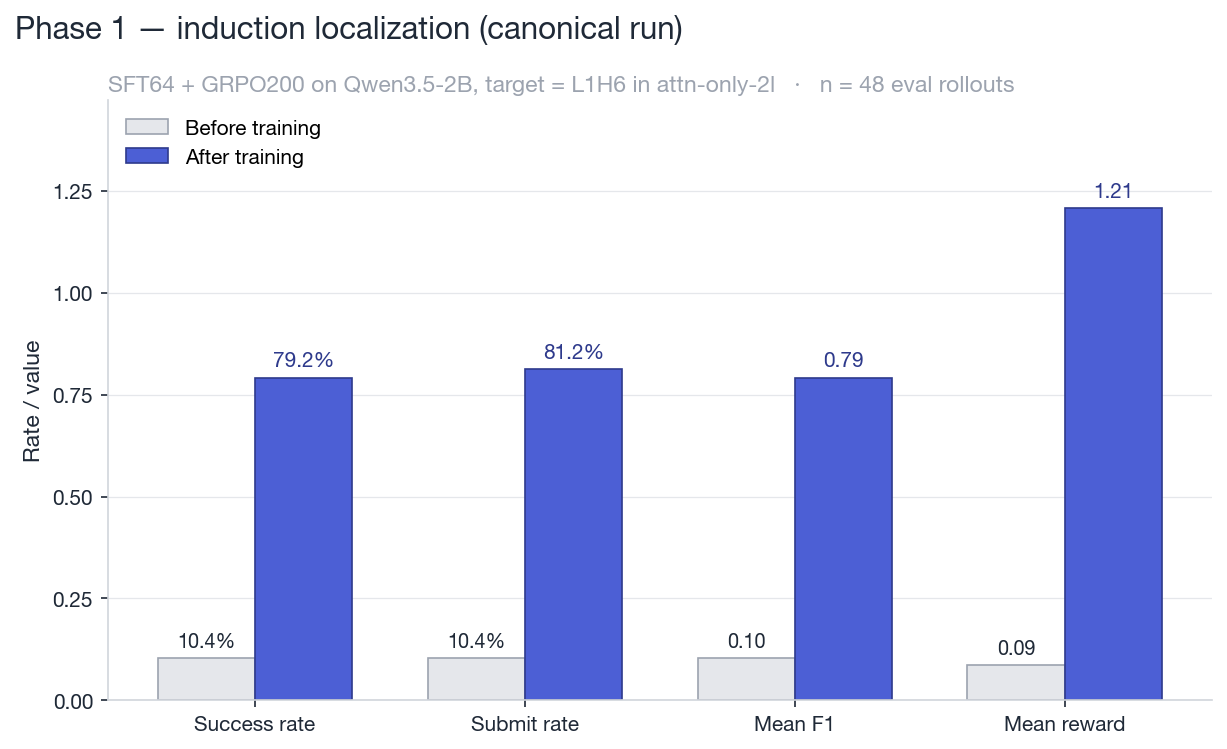
Phase 1 canonical run on 48 eval rollouts. Success, submit, F1, and mean reward all jump after SFT64 + GRPO200.
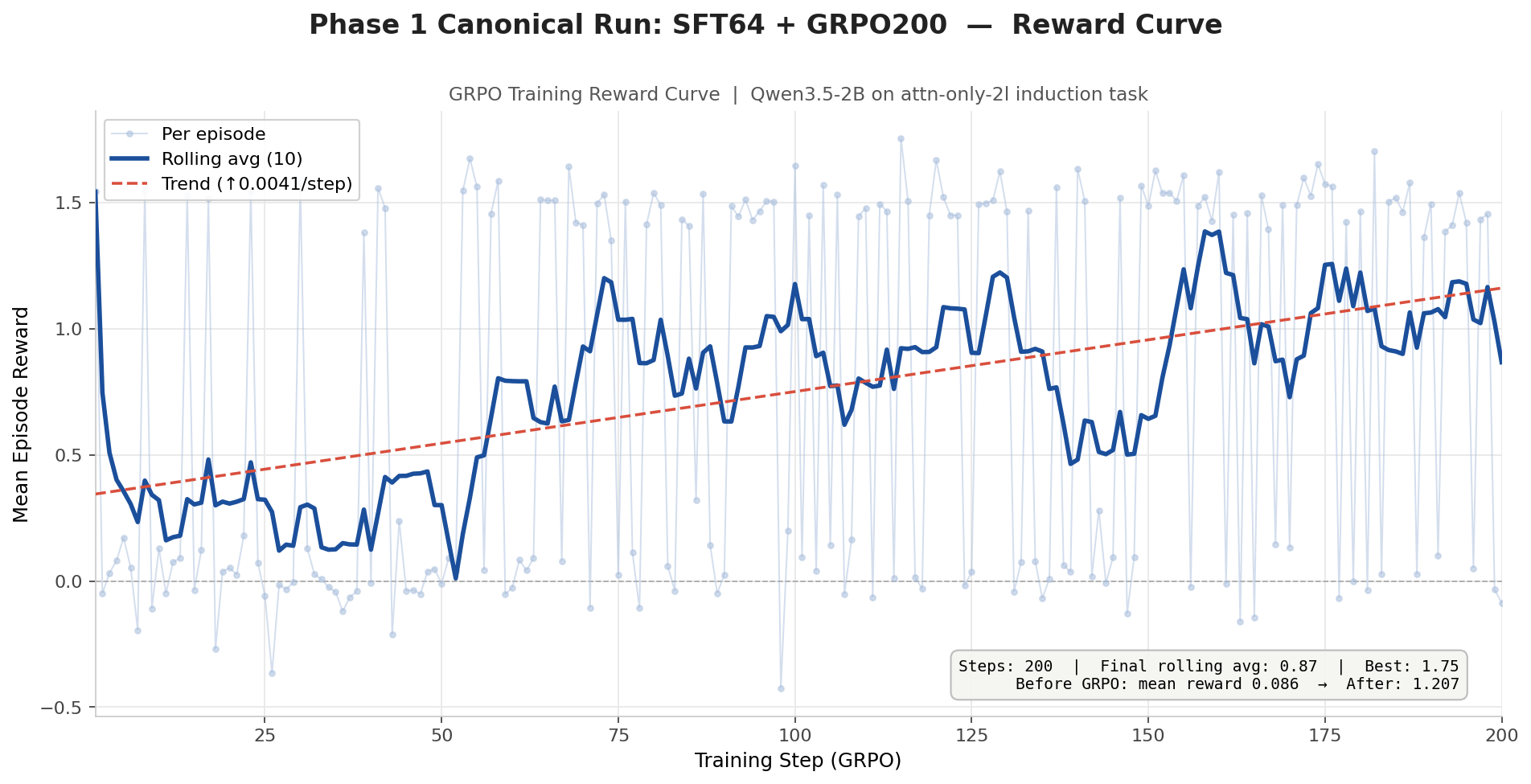
Per-step GRPO reward across 200 training steps. Per-episode reward is noisy; the 10-step rolling average shows a positive trend of +0.0041 per step, with mean reward improving from 0.086 to 1.207.
After GRPO, inspect_induction_scores appeared in 100% of eval rollouts. Successful rollouts followed the minimal protocol: inspect, read the top result, submit. Ablation usage stayed at 6.2%. The agent learned lookup, not hypothesis-driven investigation. That was enough for Phase 1 and not enough for the real goal.
The main technical lesson was simple: SFT teaches format; GRPO improves policy. Without warm-start, GRPO is shaping a model that cannot yet produce valid output. The gradient signal is mostly wasted. This matches the cold-start lesson from DeepSeek-R1 and related work on bootstrapping RL with supervised data.
The causal version
Phase 2 changes the reward. The agent only earns full credit if it submits a head it previously ablated, and that ablation produced a meaningful behavior drop. The right answer is no longer sufficient. The agent has to use causal evidence.
Shortcut: correct answer, no causal evidence
The first Phase 2 run kept the same toy transformer but penalized unablated submissions while leaving correct-but-unablated submissions slightly positive. Result on 48 eval rollouts:
| Metric | Value |
|---|---|
| Task success | 83.3% |
| Submit rate | 85.4% |
| Ablate rate | 12.5% |
| Causal success | 0.0% |
The agent submitted the correct head 83% of the time and never ablated it first.
That is not just a failed run. It shows the reward function catching a shortcut. A final-answer benchmark would mark the run as a success. Circuit Detective marked it as a failure because the agent got the right answer without doing the causal check.
Freeze: evidence gathered, no submission
The second variant made the reward stricter: heavy bonus for ablating, severe penalty for unverified submission. The agent responded by ablating constantly and refusing to submit.
| Metric | Value |
|---|---|
| Ablate rate | 95.8% |
| Submit rate | 2.1% |
| Causal success | 0.0% |
This was the opposite failure. When unablated correct submissions became worth zero reward, the agent learned to gather evidence and stop. The gradient path from intermediate ablation reward to terminal submission reward was broken, and the model stayed on the plateau it could reliably reach.
What the rubric exposed
The rubric component scores explain the failure modes more clearly than task success alone:
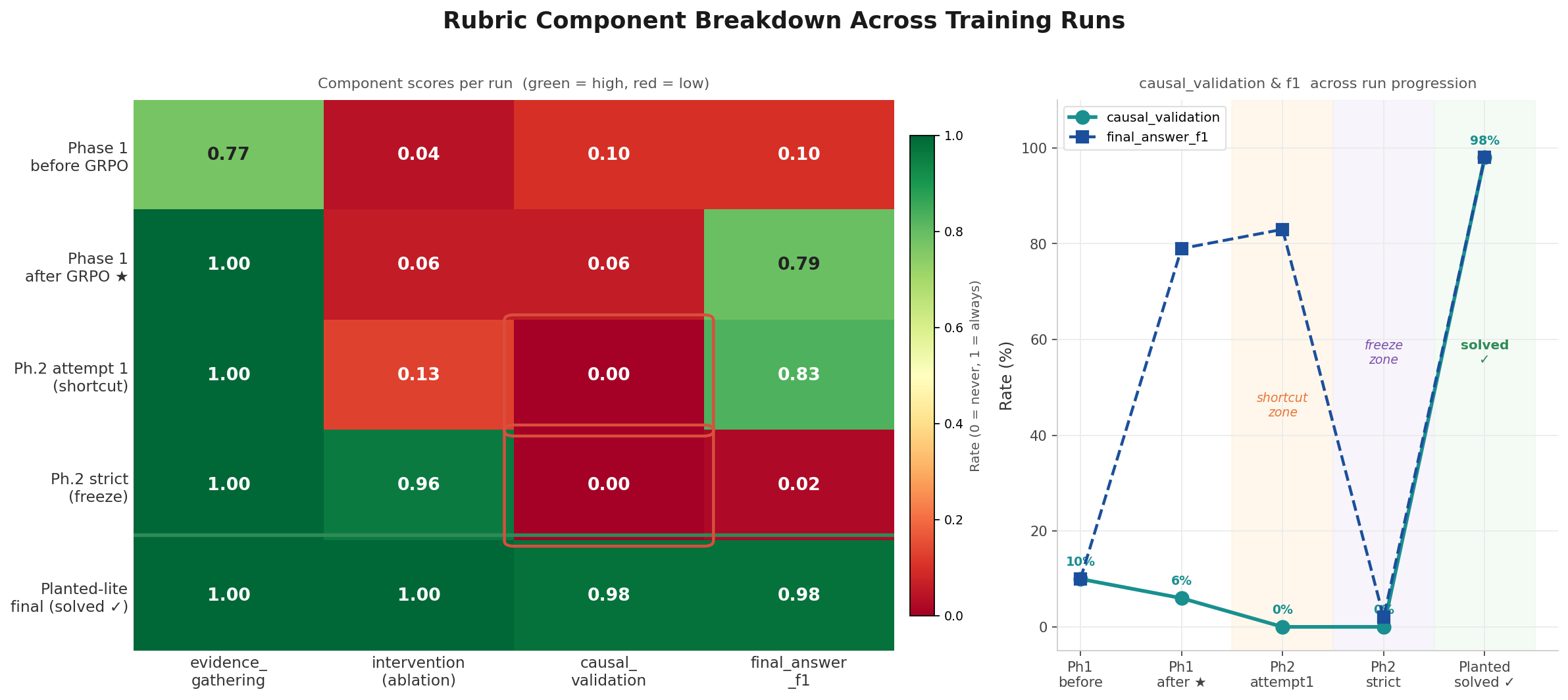
Left: rubric component heatmap across five training stages. Green is high, red is low. Right: causal_validation and final_answer_f1 across the same stages, with the shortcut zone and freeze zone annotated. Both pathologies are invisible to a final-answer benchmark.
The two Phase 2 failure modes matter together:
- Shortcut: the shortcut survives because the reward allows it. This proves the causal criterion is necessary.
- Freeze: the freeze happens because the terminal action has no gradient path once intermediate reward saturates. This proves the terminal signal must be distinct from the intermediate signal.
A simpler environment that scores only final answers would not expose either failure.
The freeze in one plot
The clearest visualization came from running the same task with three reward designs and tracking ablation rate against submit rate during GRPO:
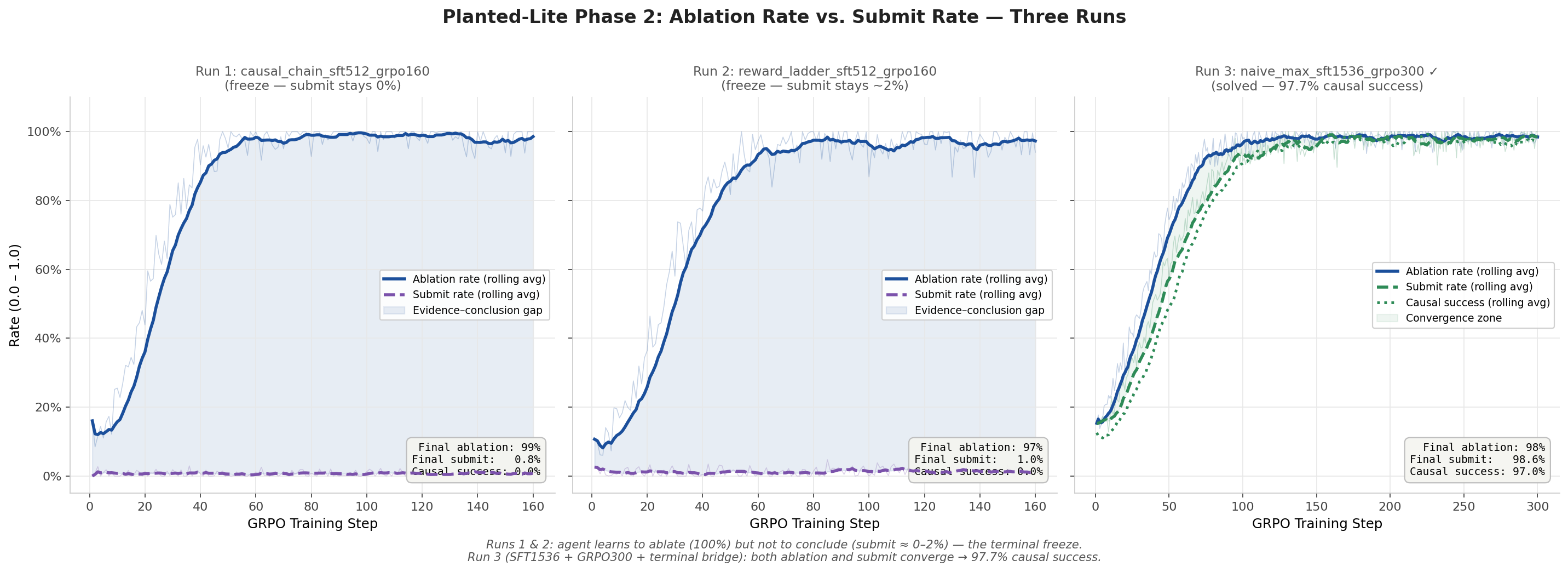
Three Phase 2 runs on the planted-lite causal-chain task. Run 1: ablation rate climbs to 99% while submit rate stays at 0%. Run 2: the same pattern, with submit barely moving to 1.6%. Run 3: terminal bridge plus SFT clinic, where both ablation and submit converge near 98%, producing 97.7% causal success.
This is the agent-training problem in one plot: knowing the correct answer and having the correct interactive policy are different training objectives. A model can know what the right action is from SFT and still fail to execute it at the right point in the rollout.
The fix
After the freeze runs, three concrete changes fixed the terminal-action failure.
1. Terminal bridge in the environment. When all candidates are ablated, the observation now explicitly tells the agent what must happen next:
{
"next_required_tool": "submit_circuit",
"next_required_arguments": {"heads": ["LxHy"]},
"terminal_action_required": true,
"must_submit": "LxHy"
}The agent does not need to infer the terminal action from sparse reward. The observation gives it directly.
2. Strict observation compaction. Live GRPO rollouts were emitting verbose observations that did not match the SFT trace format: repeated tool lists, excess metadata, and fields the clinic examples never saw. If the GRPO observations differ structurally from the SFT traces that taught submit_circuit, the terminal behavior does not transfer. This is the same kind of distribution-shift problem offline RL runs into when training data and rollout data have different structure.
3. Targeted terminal SFT clinic. Instead of adding more full-chain traces, I expanded the SFT dataset with examples for the specific failing transition: an observation where next_required_tool=submit_circuit is explicit, followed by the correct call. With 16 examples per prompt variant, the preflight produced 864 terminal-submit records out of 1,152 total.
The final causal run
The canonical Phase 2 run is planted_lite_naive_max_sft1536_grpo300_ctx1024: 1536 SFT steps on the terminal clinic, then 300 GRPO steps with terminal-bridged observations.
| Metric | Before training | After training |
|---|---|---|
| Causal success | 94.9% | 97.7% |
| Task success | 94.9% | 97.7% |
| Submit rate | 95.7% | 98.0% |
| Ablate rate | 99.2% | 100.0% |
| Mean F1 | 0.949 | 0.977 |
| Mean reward | 4.70 | 4.87 |
| Eval rollouts | 256 | 256 |
Dominant tool sequence after training: inspect_induction_scores -> ablate_head -> ablate_head -> submit_circuit, appearing in 251 of 256 rollouts.
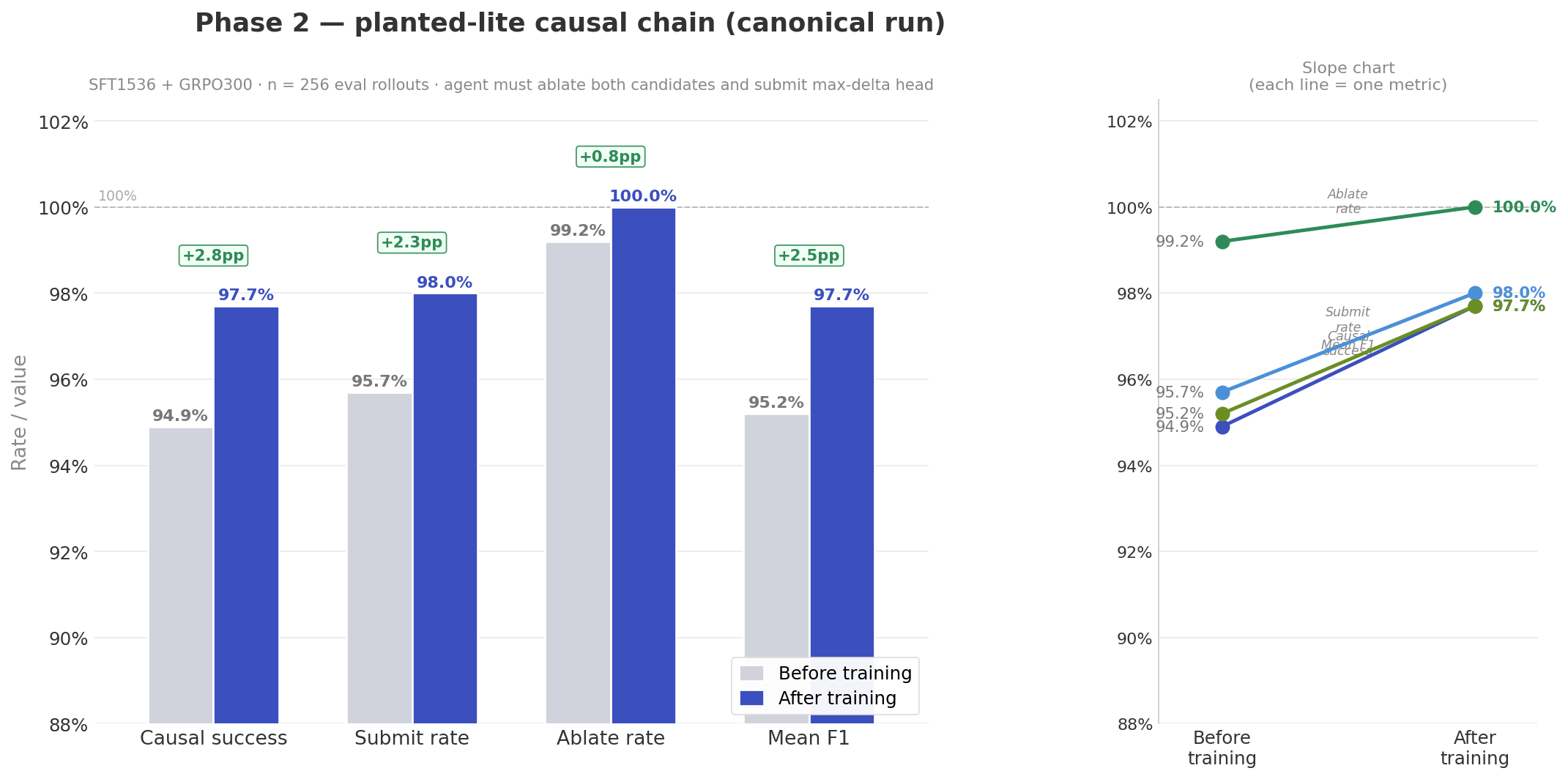
Phase 2 canonical run on 256 eval rollouts. The zoomed bars make the GRPO contribution visible on top of the already-high SFT baseline: causal +2.8pp, submit +2.3pp, ablate +0.8pp, F1 +2.5pp.
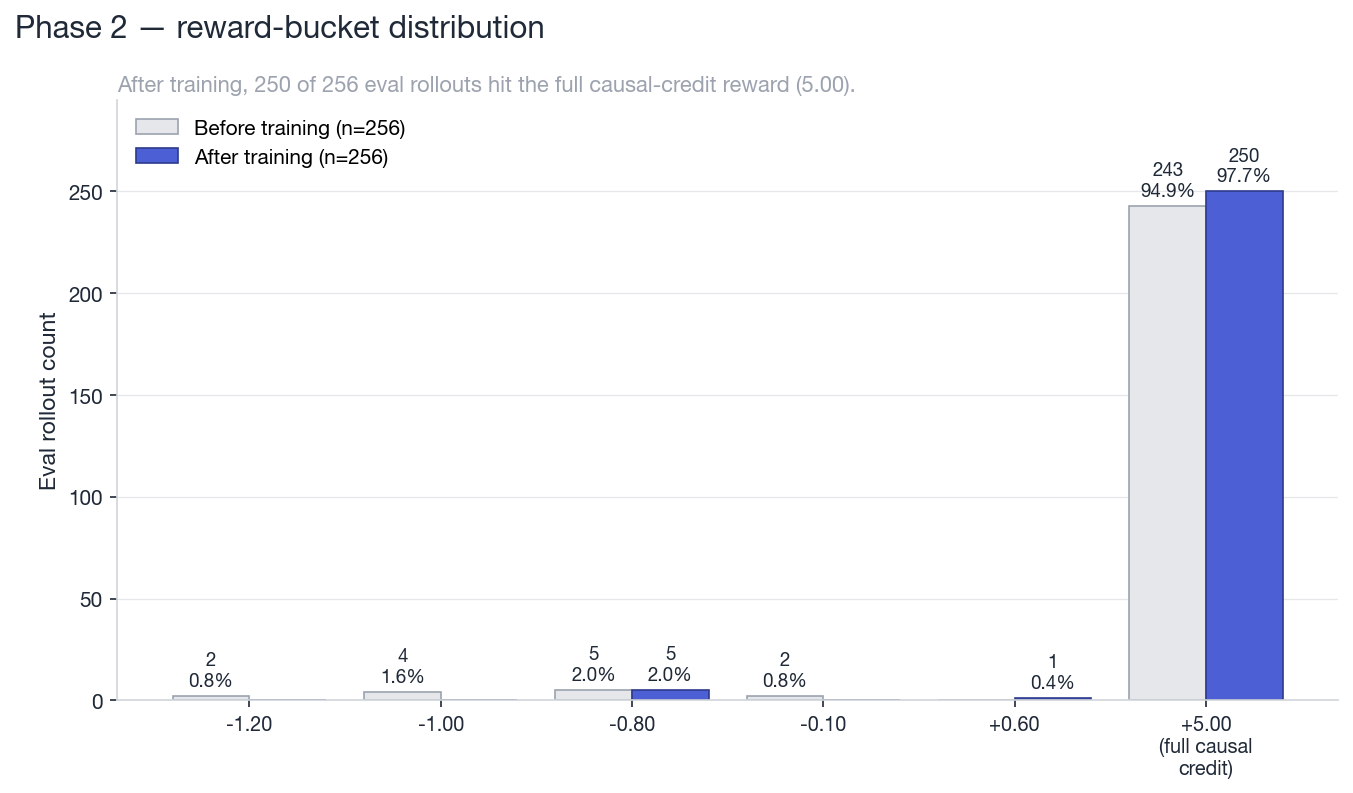
Reward-bucket distribution across 256 eval rollouts. After training, 250 of 256 rollouts land in the full-causal-credit bucket at +5.00. Five hit the wrong-head penalty at -0.80, and one hits the partial-credit bucket at +0.60.
Trained adapter: circuit-detective-qwen35-2b-planted-lite-naive-max-lora.
What SFT did vs what GRPO did
The Phase 2 result is strong, but the decomposition matters.
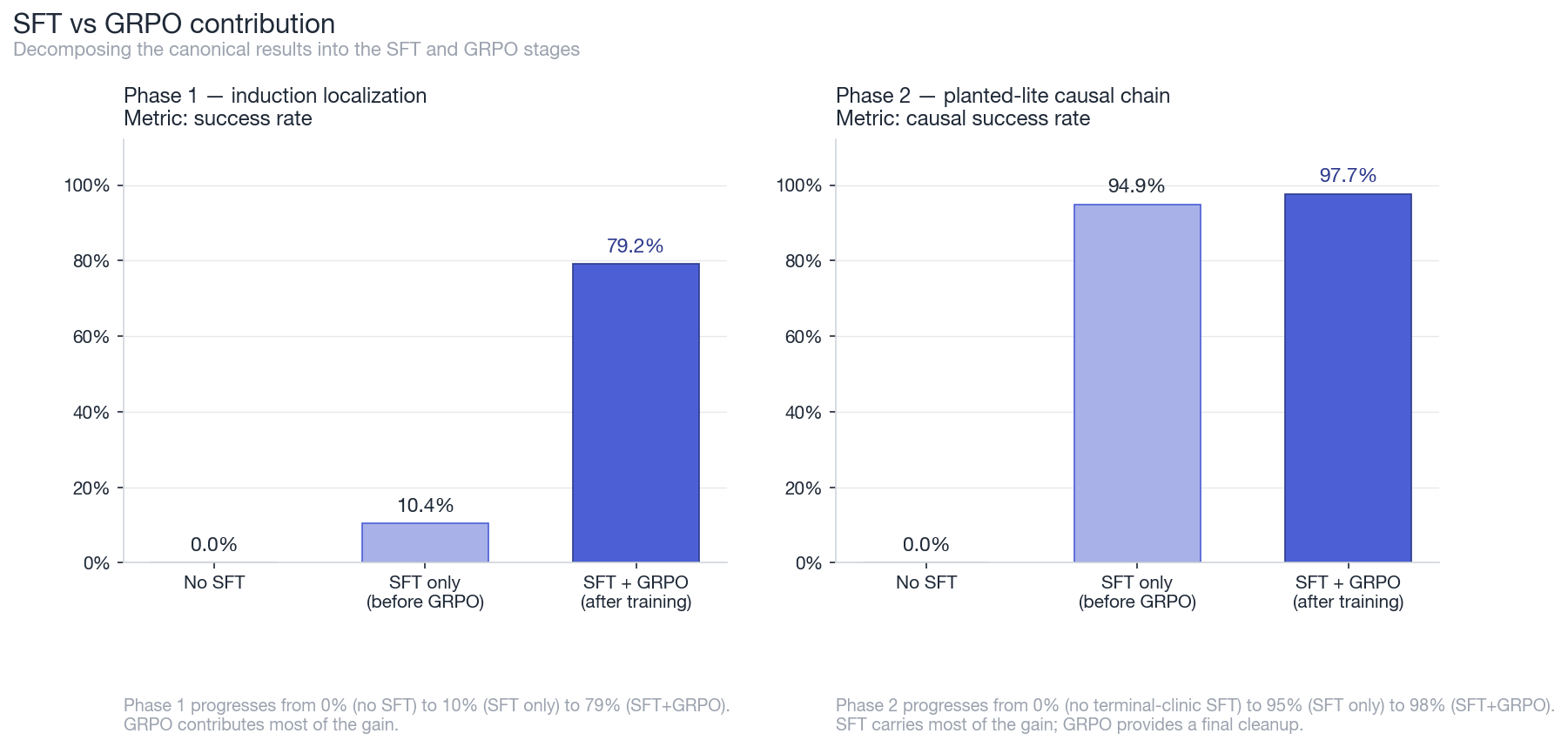
Decomposing each canonical run into its SFT and GRPO contributions. Phase 1: no-SFT GRPO produces 0% success, SFT alone produces 10%, and SFT+GRPO produces 79%. Phase 2: the targeted SFT clinic carries most of the gain, moving causal success from 0% to 95%. GRPO cleans that up from 95% to 98%.
In Phase 1, the canonical result is mostly GRPO. The SFT warm-start was tiny, only 64 steps, and got the model to 10% success. GRPO did most of the work from 10% to 79%.
In Phase 2, the result is mostly SFT. The 1536-step terminal clinic already reaches 95% causal success before GRPO begins. GRPO contributes a real but smaller improvement from 95% to 98%.
So the claim is not “RL discovered the whole behavior from scratch.” The claim is narrower: Circuit Detective exposed a real agent-control failure, first the shortcut and then the freeze, and the environment was iterated until it produced a clean training signal for the full causal-evidence chain.
What I am not claiming
IOI on real GPT-2 small. The TransformerLens GPT-2-small backend is implemented and produces sensible ablation deltas, with baseline logit-diff around 4.05 and top measured head L8H10. Training produced only marginal F1 improvement, from 0.0 to 0.006, and no solved trajectories. IOI was too hard before the smaller causal-chain protocol worked. It belongs in the roadmap.
Randomized planted circuits. Across multiple runs with randomized targets, the model learned to either submit frequently or ablate frequently, but not both in the right sequence. This failure mode motivated the simpler planted-lite design.
End-to-end RL discovery. The SFT-vs-GRPO chart is the honest decomposition. Most of Phase 2’s gain comes from targeted SFT.
What comes next
Phase 1 shows that a small model can learn the basic interpretability protocol under GRPO. Phase 2 shows that the causal version of the protocol is learnable when the environment, SFT data, and reward are designed together. The next steps are clearer now.
Near term. The next milestone is a planted-lite arena with randomized targets where the trained policy generalizes without further fine-tuning. Once that works, the same agent should locate IOI name-mover heads in GPT-2 small using the TransformerLens backend already wired into the repo.
Medium term. The scientific question I care about most is whether a policy trained on one model family transfers to another. If an agent trained to find induction heads in attn-only-2l can locate analogous structures in Pythia-70M or GPT-2 small without retraining, that is evidence of skill acquisition rather than memorization of one model’s weights. Representation universality suggests many circuit motifs recur across architectures, so the policy should learn the investigation procedure, not just a list of heads.
Longer term. The full version is an agent that can be pointed at a new model, given a behavior of interest, and run an investigation without step-by-step human guidance. That requires combining circuit localization with causal tracing, sparse autoencoder feature identification, and multi-step hypothesis revision. Circuit Detective is a first training environment for that kind of policy.
What this would mean for AI safety. Scalable oversight and interpretability-based alignment both need ways to understand what a model is doing internally at scale. A trained circuit-localization agent would be a different kind of tool from a script or a static benchmark. The sleeper agents problem, where hidden behaviors activate only under specific conditions, is exactly the kind of problem this style of agent could help investigate.
The reward-design finding generalizes beyond interpretability: GRPO can train a model to exploit a reward shortcut while learning no causal procedure, and a composable rubric can expose that shortcut. Circuit Detective made the failure visible because the environment scores the investigation process, not just the submitted answer.